【Python】Pandas practice
去年11月にスクールで習ったPandasのまとめ。
いつか、何かに役立つかと、備忘録。
date-written: 2019.11.08
Colaboratoryのにゃんにゃんは、
11月はずっとハロウィンのようで、毎日愉快な勉強できているこの頃です。
ここ最近、午前中はPython。
この前、Pandas勉強したので。せっかく勉強したから忘れる前に、備忘録。
CSVデータをエクセルで動かすのをPythonで復習。
Pandasまとめ
・Pythonのライブラリ、データの前処理に使う便利ライブラリ。
・データに「インデックス」をつけて表示できる。
・1,Series 2,DataFrameの2種類ある。
—–
1, Series
DataFrameが1つのカラム(一次元)を指すデータ構造
2, DataFrame
DataFrameが二次元のデータ構造
—–
pandasの読み込み
import pandas as pd
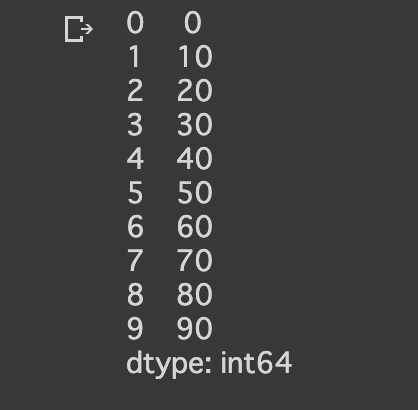
#pandas使うと、インデックスがついになった配列となる。
sample_pandas_data = pd.Series([0, 10, 20, 30, 40, 50, 60, 70, 80, 90])
sample_pandas_data
こういうimportもある↓
が、Numpyとこんがらがらないよう、pd.つけたやり方がよさそう。
#pandasのシリーズとデーターフレームを使いますよ。
from pandas import Series, DataFrame
#fromで読み込むと、下記の.pd省略できる
sample_pandas_data = Series([0, 10, 20, 30, 40, 50, 60, 70, 80, 90])
1,Series
・一次元のデータ構造
・.Series()関数
[インデックス指定なし]
#インデックス指定なしのSeries
sample_pandas_data = pd.Series([0, 10, 20, 30, 40, 50, 60, 70, 80, 90])
sample_pandas_data
指定しないと、さっきの0〜インデックスつく
ちなみに、通常のpythonのリストだと・・・
#通常のpython 上記のpdとの違い、インデックスは表示されない。
py = [0, 10, 20, 30, 40, 50, 60, 70, 80, 90]
py

[インデックス指定あり]
# 引数にインデックス指定できる
#.Series()関数の中に宣言。辞書みたいなカタチだね。
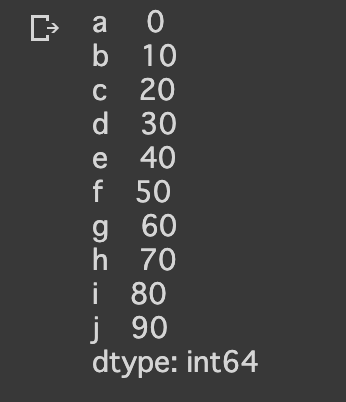
sample_pandas_index_data = pd.Series([0, 10, 20, 30, 40, 50, 60, 70, 80, 90],
index=['a','b','c','d','e','f','g','h','i','j'])
sample_pandas_index_data
2,DataFrame
・二次元のデータ構造
・DataFrame()関数
・リスト型のバリューを持ったディクショナリか、Numpy配列を使用できる。
・Seriesと同じように自動的にインデックスされる。
****************
CSVデータをリストにして、インデックスつける想定で、
2データを作成(架空データ)し、練習。
****************
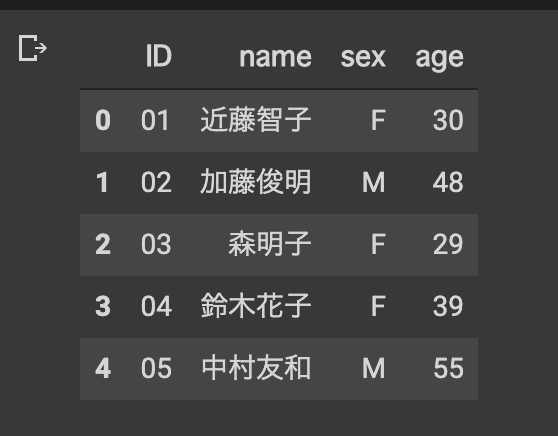
[データ1作成]
#データ1作成 #第二引数に、インデックス指定できる。
shop_data = [['01','02','03','04','05'],
['近藤智子','加藤俊明','森明子','鈴木花子','中村友和'],
['F','M','F','F','M'],
[30,48,29,39,55]]
shop_data_frame = pd.DataFrame(shop_data,
index =['ID','name','sex','age'])
#引数に指定したインデックスは、行に入るので、.Tで転置。
data_1= shop_data_frame.T
data_1
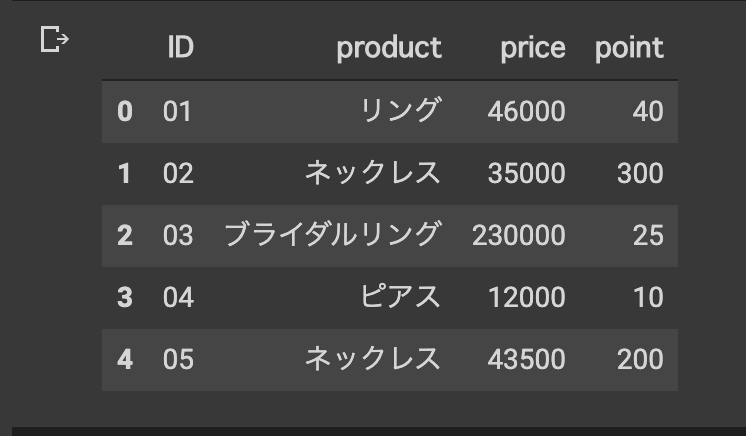
[データ2作成]
#データ2作成
shop_data2 = [['01','02','03','04','05'],
['リング','ネックレス','ブライダルリング','ピアス','ネックレス'],
[46000,35000,230000,12000,43500], [40,300,25,10,200]]
shop_data2_frame = pd.DataFrame(shop_data2, index= ['ID', 'product','price','point'])
data_2 = shop_data2_frame.T
data_2
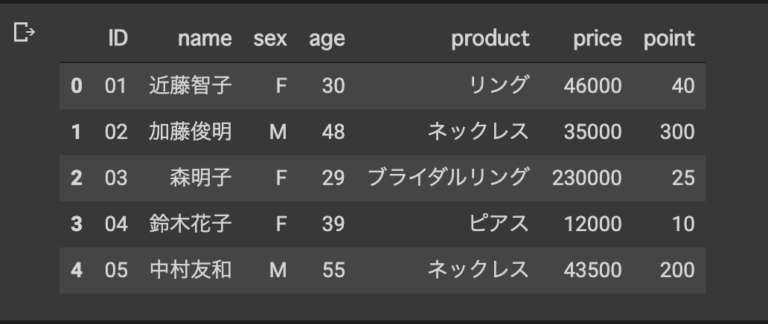
[データの結合]
#merge id名が重なっている同士が重なる
#データ1とデータ2の結合
merge_data = pd.merge(data_1,data_2)
merge_data
[インデックスの追加]
#Seriesの代入 shopを追加してみる
val = pd.Series(['表参道','渋谷','新宿','新宿', '渋谷'], index=[0,1,2,3,4])
merge_data['shop'] =val merge_data
#ちなみに削除は、 del
#del merge_data['shop']
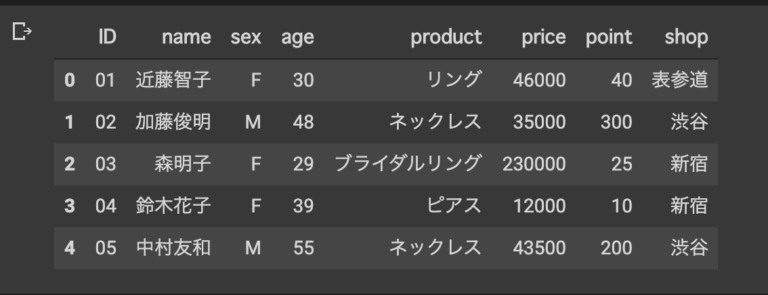
[インデックスの並び替え:.reindex()]
#.reindex()インデックスの並び順が変更できるよ
merge_data.reindex(columns=['ID', 'shop','product','price','point','name','sex', 'age'])
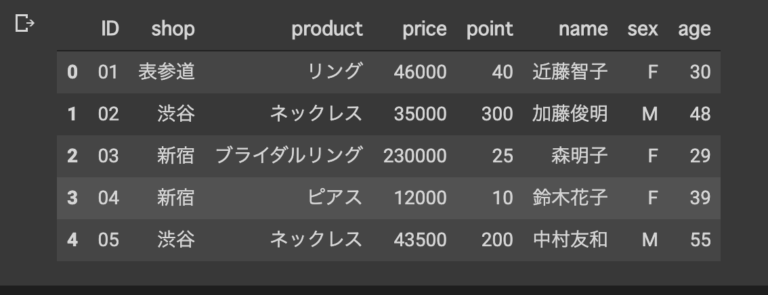
[インデックス名を変更:.rename() ]
#.rename() インデックス名を日本語名に変更してみる
merge_data.rename (columns = {'ID':'id', 'name':'名前', 'sex':'性別', 'age': '年齢', 'product': '商品名', 'price': '購入額','point': 'ポイント'})

[merge_dataから、要素抽出]
—————-
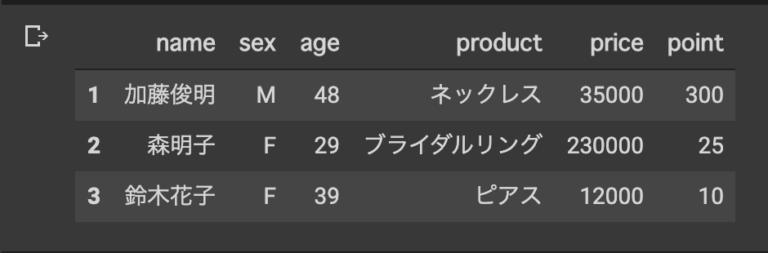
**loc属性**
#loc [id:id,'インデックス名':'インデックス名']
#行をidで指定、列はラベル名(インデックス)で指定 merge_data.loc[1:3,'name':'point']
—————-
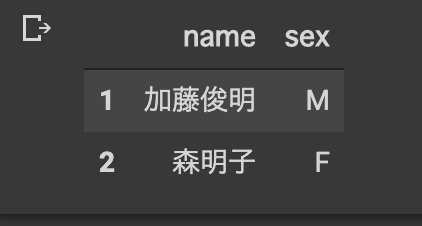
**iloc属性**
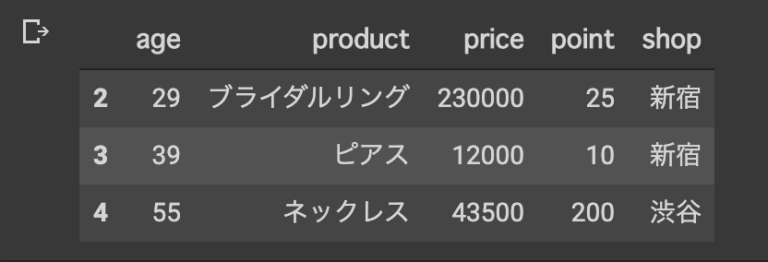
#項目は考えないで、0から数えて指定 #1:3は、1~2まで抽出ってこと。 merge_data.iloc[1:3, 1:3]
#2:空欄 は、2~全部ってこと。
merge_data.iloc[2:,3:]
—————-
**属性使わずに列データ抜き出す**
#.インデックスでshop列を全部取り出せるが、
#Jupyter特有の記述方法で、使わない方が賢明とのこと
merge_data.shop
#特定の列の抽出は列のキーを指定 ['インデックス']
#上と同じ結果 単一のブラケットで囲むとSeries型になる
merge_data['shop']

#単数取り出しも、二次元(ブラケット二つつける)と表になる。
# ブラケットで2重に囲むDataFrame型になるから
merge_data[['shop']]
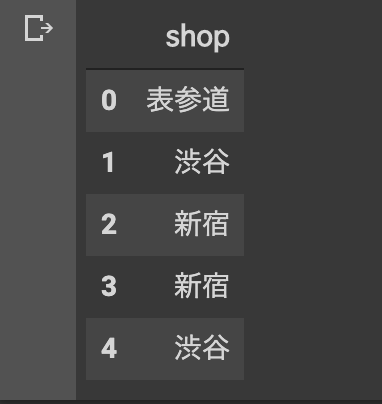
shop列の表参道のみ取り出す
#Series型で取得
merge_data['shop'][0]
#DataFrame型で取得、これも出るけど複雑なのは使いたくないね、
merge_data[['shop'][0]][0]]]
name列とproduct列を取り出す
# 配列のカタチになっているね
merge_data [['name','product']]
—————-
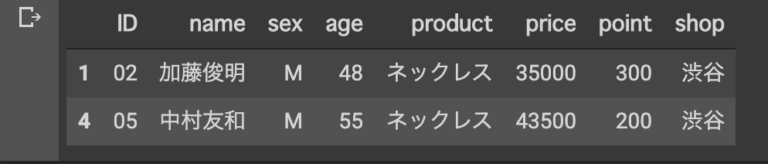
**.isin()**
#男性の購入者
merge_data [merge_data['sex'].isin(['M'])]
—————-
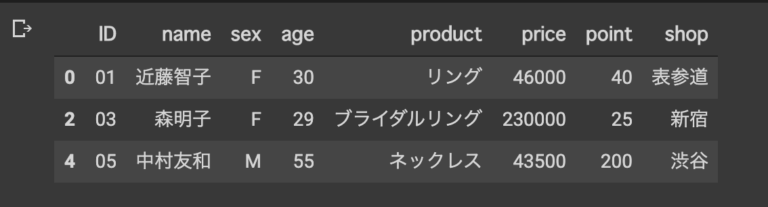
**比較演算子使う**
#購入金額が4万円以上の人
merge_data [merge_data ['price'] >= 40000]
—————-
**集計:groupby()**
groupby()を使うとグループ集計できる
**合計:.sum()**
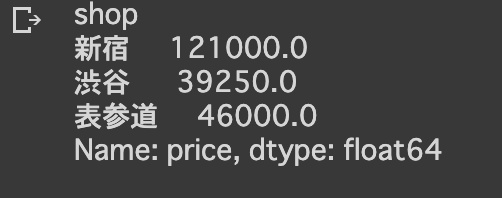
#各ショップの合計金額
merge_data.groupby('shop')['price'].sum()

—————-
**平均:.mean()**
#.mean()したら、numericじゃないよエラーに。なぜ?
#pythonのリストはpandasだと Numpy配列になり、数値がnumericじゃなくなのか?
#いろいろ調べて、教わって、numeric_only = Noneをしてエラーなくなる。。。うむむ。
merge_data.groupby('shop')['price'].mean(numeric_only = None)
—————-
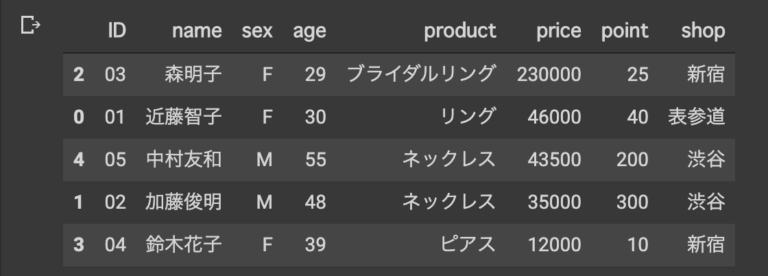
**指定した値でソート:sort_values()**
#購入額高い順 merge_data.sort_values(by=["price"],ascending=False)
#ascending=True (値が小さい順)
#ascending=False 降順(値が大きい順)
—————-
**先頭から指定した行を表示:head()**
#指定しないと5行表示になる
merge_data.head(3)
—————-
**終わりから指定した行を表示:tail()**
#指定しないと5行表示になる
merge_data.tail(3)
—————-
[merge_dataから、要素削除]
**削除:drop**
axisの値が、
・0なら行
・1なら列
#shop列の削除
merge_data.drop(['shop'], axis = 1)
[/python]
#加藤さんの行を削除
merge_data.drop([1], axis = 0)